Sql Vs Nosql: How Slack And Discord Store Trillions Of Messages
Summary
Discord and slack are two of the most popular group message applications. Discord gained its popularity through the game community, and slack is focused on serving business/enterprise workspaces. Both of these two applications need to store a huge amount of messages permanently.
- Discord stores trillions messages at 2023
- Slack supported 65+ billion daily queries, with a storage of 9+PB and thousands of DB nodes in 2020.
Both of these two companies shared their storage infra to the tech community via tech talk in conferences and tech blog articles, so we could get insights of their solutions.
It is very interesting that these two companies use two totally different approaches. Slack used MySQL since the very beginning and kept optimizing it since then. In contrast, discord started with storing messages in MongoDB, then switched to cassandra in 2017, recently Discord migrated to message storaged to an optimized ScyllaDB cluster with a Data Service layer written in the Rust language.
To put it in a simple way: Slack uses a SQL based solution and Discord uses NoSQL based solution. In this blog article, we are going to compare these two solutions, calling out interesting learnings from their journey.
Slack’s MySQL Cluster
Slack’s backend started as a simple LAMP architecture, it’s backend logic (the webapp) is implemented in PHP, and all state are stored in a MySQL cluster. The MySQL cluster is configured as active-active, so all nodes are master nodes and could handle write requests. The database is shared by workspace ID, i.e., the ID of the company which is also referred as the work team. There is also a messags server implemented in Java for realtime dispatch.
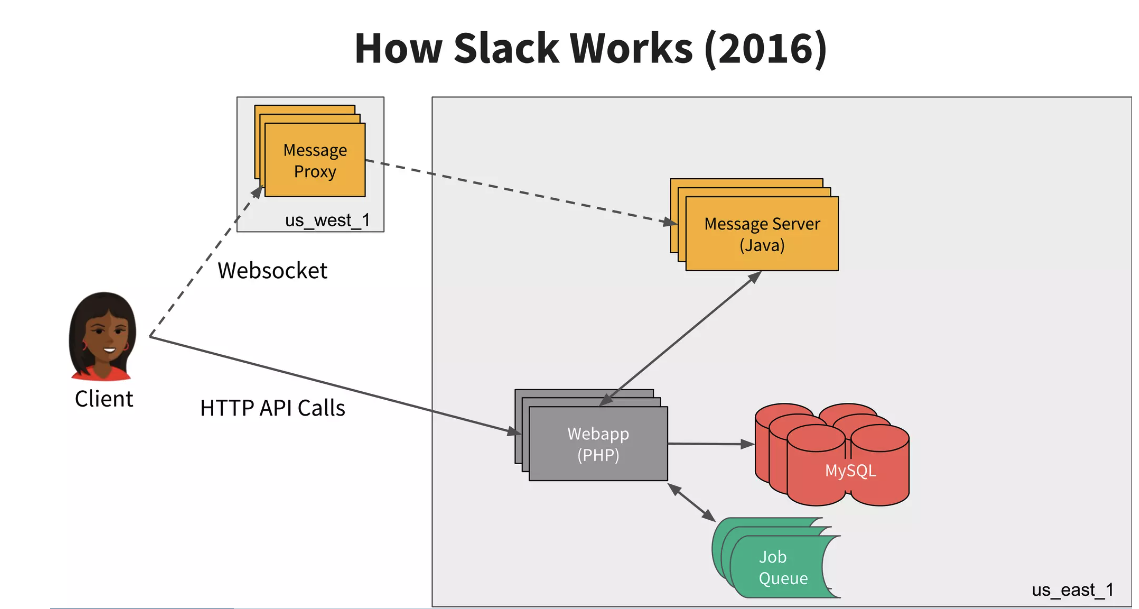 Figure: Slack Architecture in 2016
Figure: Slack Architecture in 2016
Slack’s business went viral around 2015, and kept the exponential growth till 2018. By 2018, it had 8M+ daily active users.
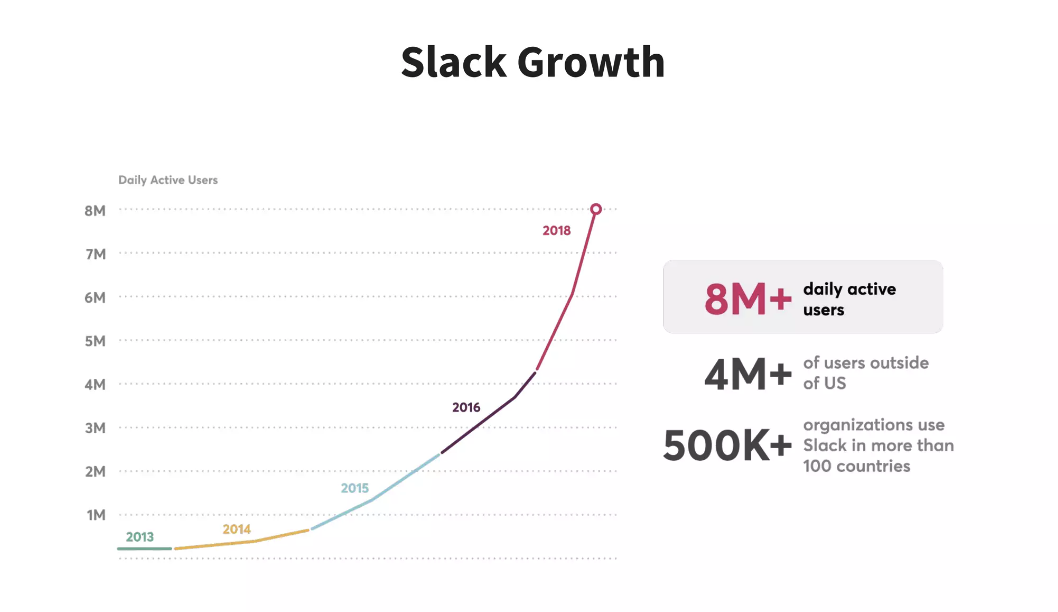 Figure: Slack’s DAU growth 2013-2018
Figure: Slack’s DAU growth 2013-2018
Back to our topic of storage, to support this type of hyper growth, Slack’s engineering team did a lot of work to scale the system, which evolved their architecture to the chart below. One of the efforts is to re-architect its storage layer; they used vitess to implement a huge MySQL clusters that supports fine-grained DB sharding.
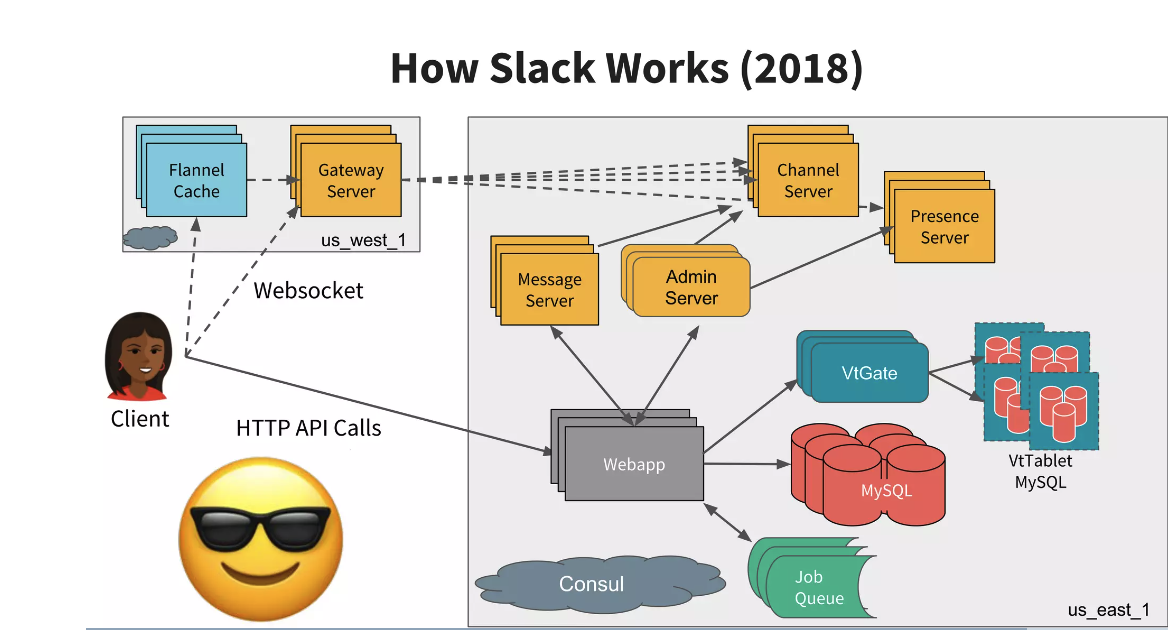 Figure: Slack Architecture in 2018
Figure: Slack Architecture in 2018
Vitess
Vitess (https://vitess.io/) is a database clustering system for horizontal scaling of MySQL through generalized sharding. It encapsulates the shard-routing logic from the application layer, and allows application code and database queries to remain agnostic to the distribution of data onto multiple shards.
Vitess was built at YouTube, and was in full production since 2011, and has grown to encompass tens of thousands of MySQL nodes in YouTube. Later, it was open sourced at https://vitess.io/, has been adopted by lots of tech companies, including wellknown brands like Pinterest, GitHub, Square and Slack etc.
Its high level architecture is listed below. Basically it adds a shim layer, called VtTable, on top of each mysqld node. It also builds a gateway component called VtGate that handles application layer quries. There is also a control node VtCtld which manages the topology of nodes. From the application layer’s perspective, the details of sharding and routing etc are behind vitess and application engineers do not need to pay attention to these details. Vitess also offers admin tools and a web console for DB Admins to config and tune the DB clsuter.
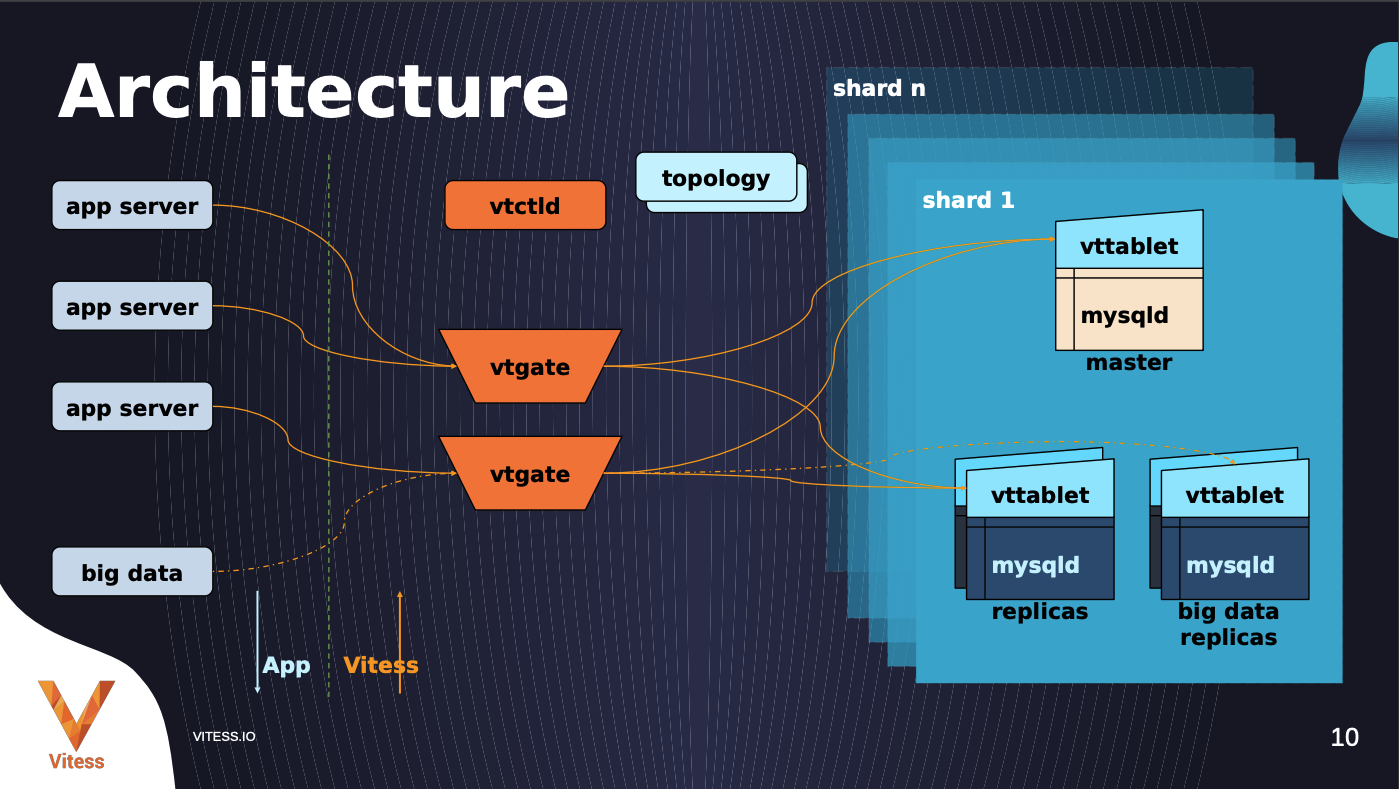 Figure: Vitess architecture
Figure: Vitess architecture
Slack’s Vitess Adoption
Comparing with Slack’s previous master-master MySQL Cluster solution, the Vitess solution supported flexible sharding. Instead of deeply interwinding sharing logic into the application layer, vitess supports per-table sharding policy.
Vitess also supports resharding workflows that could automatically expand the cluster. It also supports a failover workflow, which orchestrates the promotion a replica on failover.
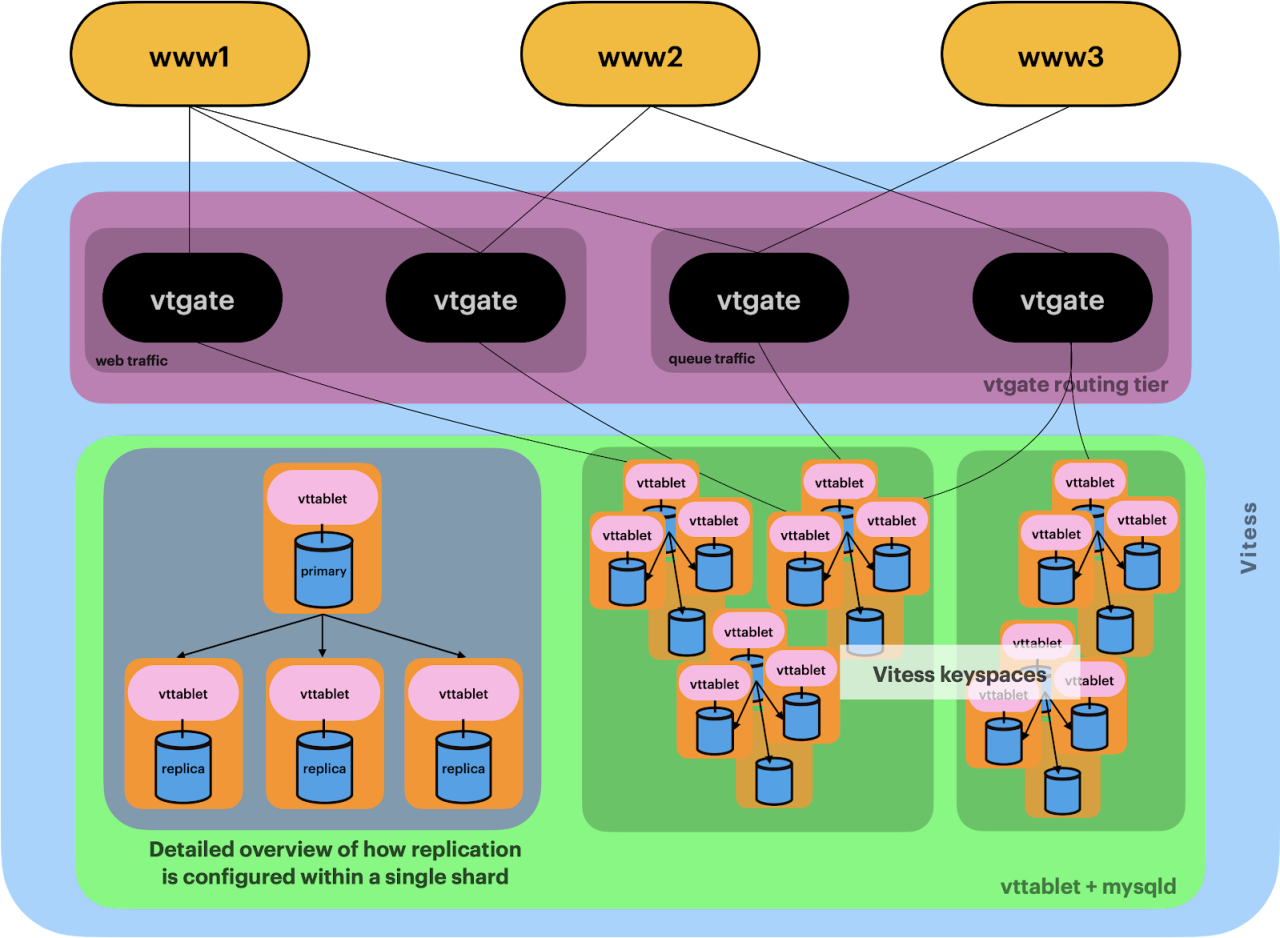 Figure: Vitess Deployment at Slack
Figure: Vitess Deployment at Slack
Slack’s Vitess migration is a very length process. It took the company 2.5 years to migrate 70% of the workload to vitess. And interestingly the 70% of traffic only involves 10 tables, which are the primary work horses of the database. I.e. these tables are the most complicated tables with the highest volume. It is not a simple migration, it was a re-architecture.
Meanwhile, with vitness adoption, Slack needs to have its own database team, and it does not use typical hosted instances like AWS RDS, instead Slack built and deployed its own DB nodes on EC2 instances directly and managed the cluster onwards.
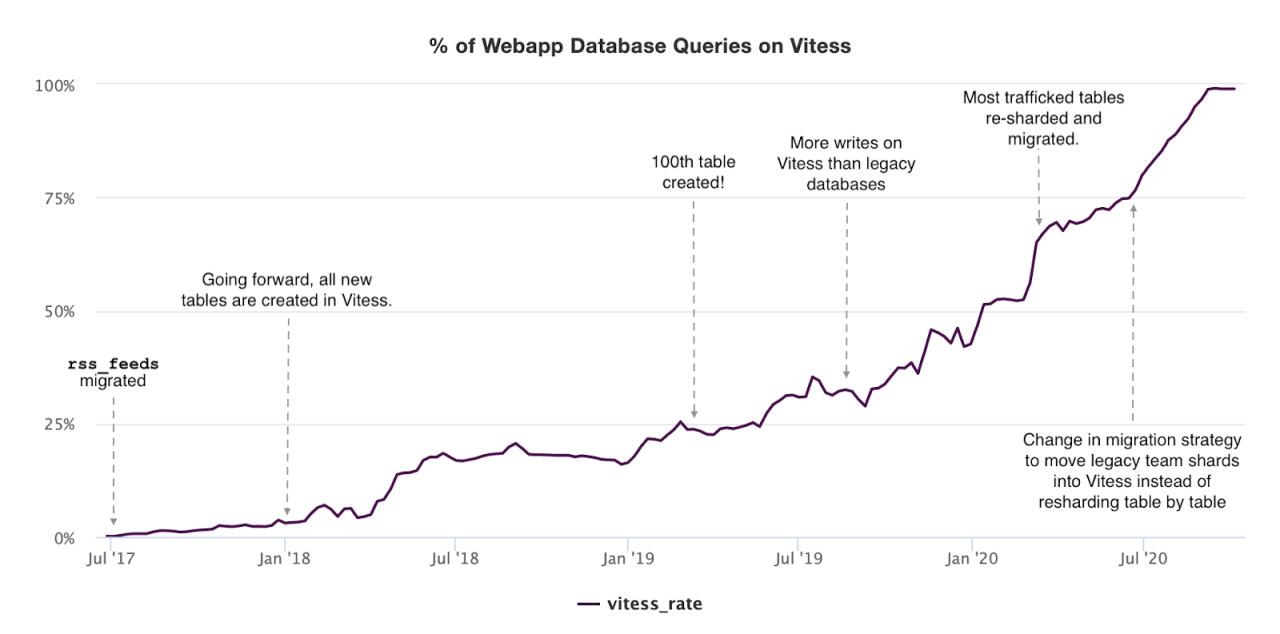 Figure: the 4 years journey of the vitess migration at Slack
Figure: the 4 years journey of the vitess migration at Slack
On the other hand, this infra investment justfied its value in mutltiple fronts.
- With Vitess, Slack upgraded from the workspace based sharding to a channel-sharded/user-sharded data model that helped mitigate hot spots for large teams and thundering herds.
- When CVOID broke out in March 2020, Slack had explosive growth demand due to work from home policy. Thanks to the vitess cluster, the team could easily scale out the DB provision to support the growth and ensure serving quality.
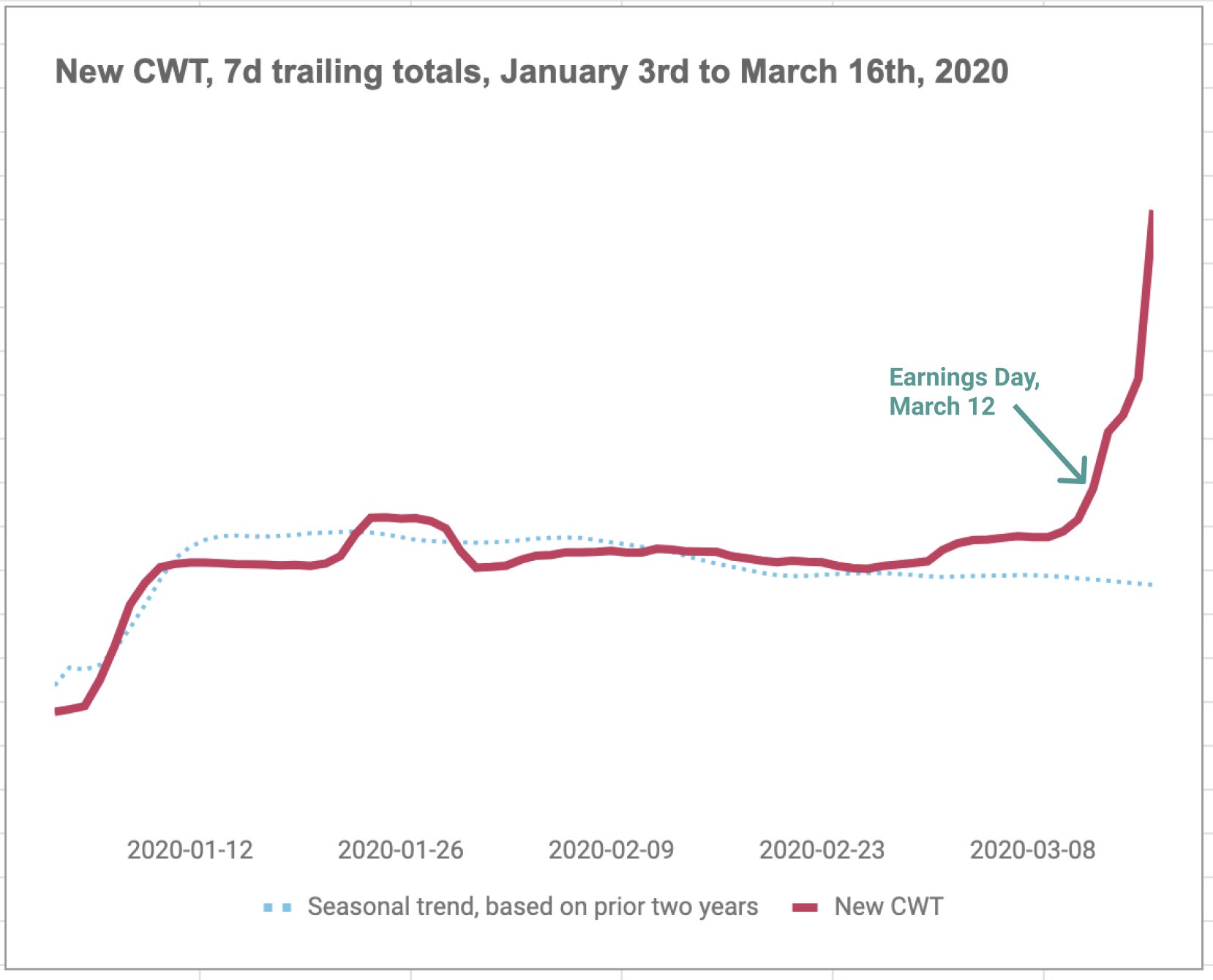 Figure: Slack’s Newly created “work teams”, 7d trailing totals, during COVID time
Figure: Slack’s Newly created “work teams”, 7d trailing totals, during COVID time
Discord
Discord is an instant messaging and VoIP social platform. Users have the ability to communicate with voice calls, video calls and text messaging in private chats or as part of a community called servers. It is primarily used by gamers.
Discord has its own unique tech choices which are related to its product nature. It uses Elixir for the Gateway/Websocket API. Its HTTP/REST API is built with python. It also uses Go, Rust and C++ to build mission critical services. Because voice/video streaming is its core feature, it uses WebRTC for such features.
Message Storage at Discord
Discord’s MVP was built in less than two months and used MongoDB as the single storage. At that time, the message table, A.K.A. document in MongoDB terms, in MongoDB used a single compound index (channel_id, created_at).
By 2015, Discord reached 100 millions stored messages in its MongoDB, and started to notice performance issue because the data and the index could not fit in RAM and latency became unpredictable, so Discord started to build its next generation of message storage, and decided to use Cassandra as the primary storage. Because Cassandra supports linear scalability, and could automatically failover on incidents, and has a proven record at large companies like Netflix and Apple and it is also open sourced, so the team has full visibility of the implementation details and does not depend on any third party company.
The Cassandra based message table is like
CREATE TABLE messages (
channel_id bigint,
bucket int,
message_id bigint,
author_id bigint,
content text,
PRIMARY KEY ((channel_id, bucket), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
The bucket is the index of a 10 day time window since epoch. The message_id is a snowflake, i.e. the chronologically sortable unique IDs generated by the snowflake system built at twitter. The (channel_id, bucket) together determined the primary cassandra sharding for the message. This helps to split heavy channels into small shards by 10 days of messages and also makes sure messages are stored together by its creation time. Discord sets the window size to 10 days so each shard is capped around 100MB in size which guarantees good performance on Cassandra.
Discord had been using this message storage solution from 2017 to 2022, and through the journey, the Cassandra message cluster grew from 12 Cassandra nodes to 177 nodes, nearly 20X of growth. The total message stored grew from billions to trillions.
By 2022, the discord team noticed the following issues of their Cassandra storages:
- The 10 day shard window could cause hotspot partitions. Basically if a server has hundreds of thousands of people and all of them interact in the community channel concurrently, the shard of the bucket will get a huge amount of read and write requests, which causes high latency and also impacts other queries in the same cassandra node.
- The node compaction routine also became very expensive and required a lot of Dev-Ops’s manual touches.
- JVM’s GC pause could also cause a significant latency spike.
To solve these problems, discord started to build its next generation of message storages, which is composed of 3 pillars.
First: Discord replaced the Cassandra cluster with ScyllaDB. ScyllaDB is Cassandra compatible storage, but is implemented in C++. Benchmark indicated tht ScyllaDB could have 2x-10x performance improvement compared with Cassandra. And ScyllaDB does not have the JVM GC Pause issue and could performance hiccup caused by long GC pause.
Second: based on the observation that popular channels could have lots of duplicated, concurrent read requests on the same content, Discord built a data service layer via Rust. The most important feature the data service layer provides is request coalescing. If multiple users are requesting the same row at the same time, it only queries the database once and share results to all these users. This data service layer uses a consistent hash based routing, so duplicated requests could hit the same node and improves cache hit rate.
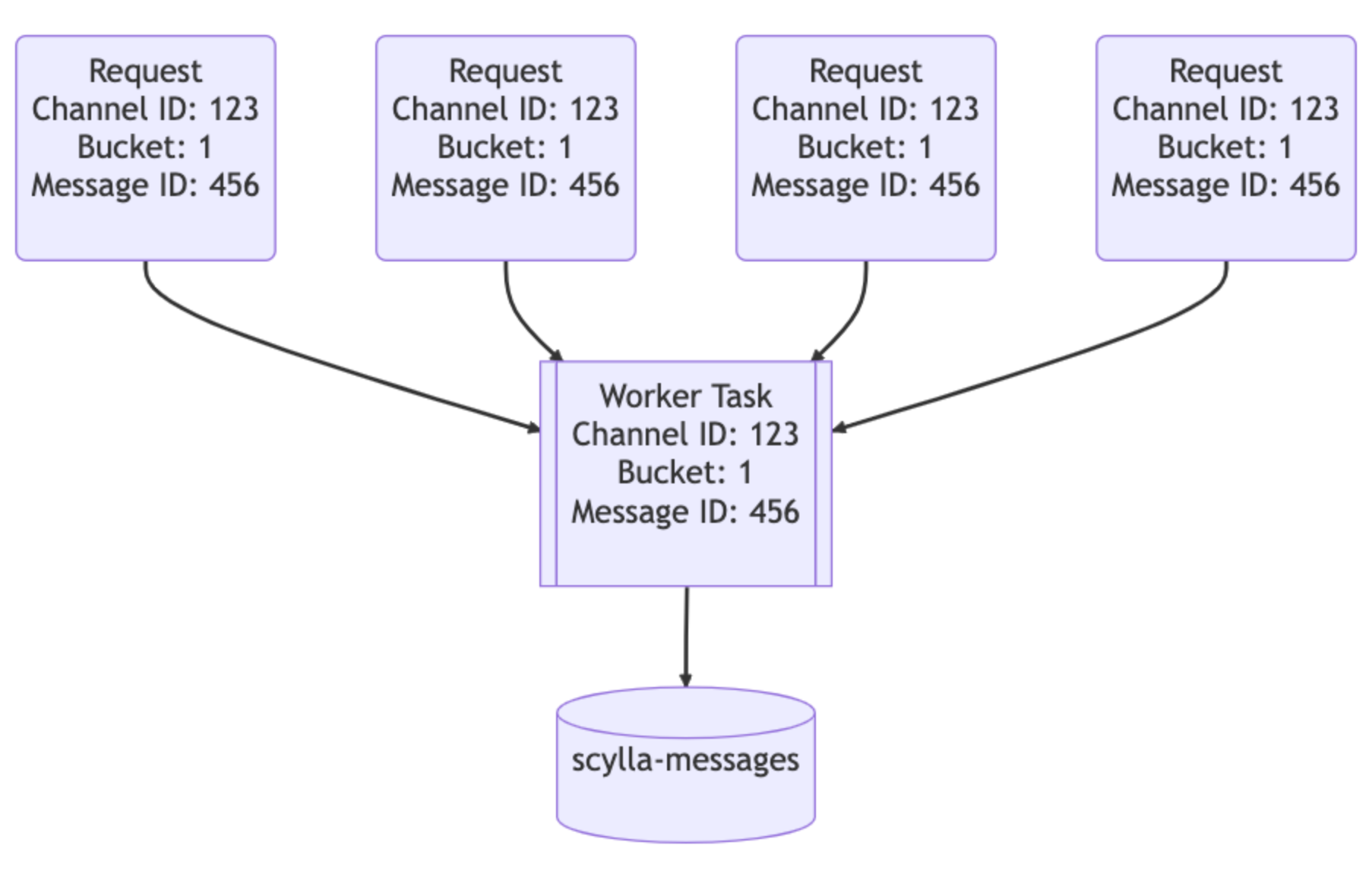 Figure: The RUST data service layer coalesces shields duplicated requests from DB
Figure: The RUST data service layer coalesces shields duplicated requests from DB
Third: this is a very low level project, called Superdisk. Basically discord built its own RAID storage combining SSD and normal disk, so it provides fast read and but also guarantee high availability if SSD is out due to host outage.
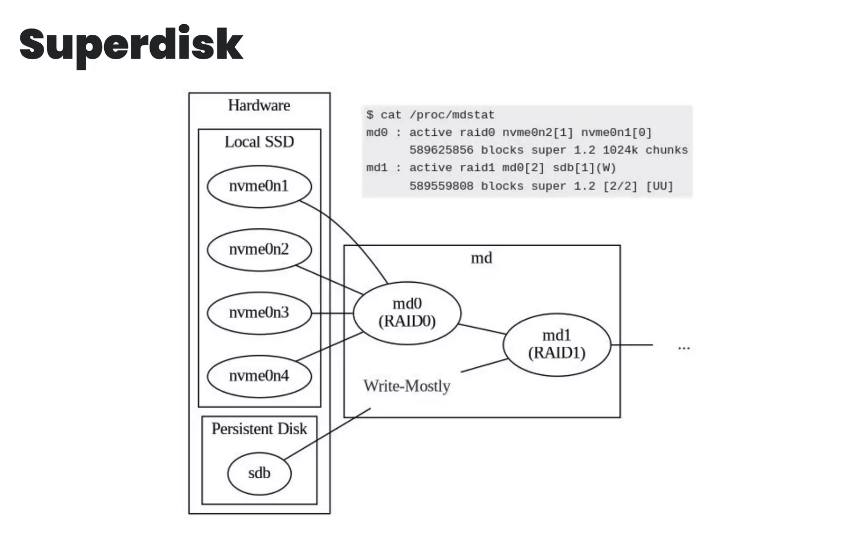 Figure: Discord’s superdisk system that powers its ScyllaDB cluster
Figure: Discord’s superdisk system that powers its ScyllaDB cluster
The performance improvement
Overall the re-architect effort is relatively straight-forward, it replaces java-based Cassandra with C++ based ScyllaDB. It uses a RUST-based “cache” layer to shield duplicated message requests at the same time. It combines an SSD and a normal disk in its RAID.
But these changes lead to big performance improvement: the system went from 177 Cassandra nodes to 72 ScyllaDB nodes. Each ScyllaDB node has 9 TB of disk space, up from the average of 4 TB per Cassandra node.
The p99 latency of reading historical messages changed from 40-125ms on Cassandra to just 15ms on ScyllaDB.
SQL vs NoSQL Storage
SQL vs NoSQL storage has been a hot topic in the engineering community in the past decade. An experienced engineer could briefly tell the difference between these two groups of systems.
It is very interesting that Slack and Discord used both SQL and NoSQL DB to solve similar technique requirements: store and serve trillions of messages. Their architectures are totally different. Here are a few take aways based on what we learned so far:
- Slack is a company that preferred mature technology with conservative eng decisions, so they used PHP, MySQL and Vitess. Discord is more risk taking in architecture decisions, so it choses MongoDB, Cassandra and ScyllaDB, and also uses new languages like Rust. But overall both companies achieved their goal via their implementation.
- Nowadays most of the startups start with cloud hosted storage solutions, and there are a lot of choices in the market from AWS, GCP and Azure. But once one start reaches certain scale, it needs to have a vision of the long term solution. Both discord and slack determine to operate their message storage in house, because of its huge volume and importance.
- Operating open-source sotrage solutions means investment of eng resources. Both companies encoutered issues and have to spend multiple eng years to tackle them.
- There could be multiple tech approaches for a given problem. Nowadays, it might feel too old-school to storage all the message records at Slack’s scale in a SQL db, but Slack did it and engjoyed the benefit of SQL engine.
Reference
- How Discord Stores Trillions of Messages
- How Discord Stores Billions of Messages
- Announcing Snowflake
- Scylla Summit 2018: Discord: The Joy of Opinionated Systems
- How Discord Migrated Trillions of Messages from Cassandra to ScyllaDB
- Why Discord is switching from Go to Rust
- Real-time Messaging - Slack Engineering
- Scaling Slack - The Good, the Unexpected, and the Road Ahead
- Scaling Slack during explosive growth
- 20000 Leagues Under the Sea: Diving Into the Slack Infrastructure
- Scaling resilient systems: a journey into Slack’s database service
- 2018 - Designing and Launching the Next-Generation Database System @ Slack - From Whiteboard to Production (PerconaLive 2018 - Santa Clara, USA
- Vitess: Sharded MySQL on Kubernetes
- 2020 - Codename VIFL - How to Migrate MySQL Database Clusters to Vitess (KubeCon 2020 - virtual conference).pdf
- Unofficial Discord API Docs: Discord’s Internal Infrastructure
- how-discord-scaled-elixir-to-5-000-000-concurrent-users