Compare Apache Flink With Apache Spark
Summary
Google totally revolutionized the big data game with their GFS, BitTable, SSTable, and MapReduce setups. Then in the open source scene, Hadoop came in hot with HFDS, Hive, and Hadoop, offering similar firepower. But hold on, there’s more! Some new data processing platforms popped up in the ecosystem, bringing in fresh functions that Hadoop couldn’t handle.
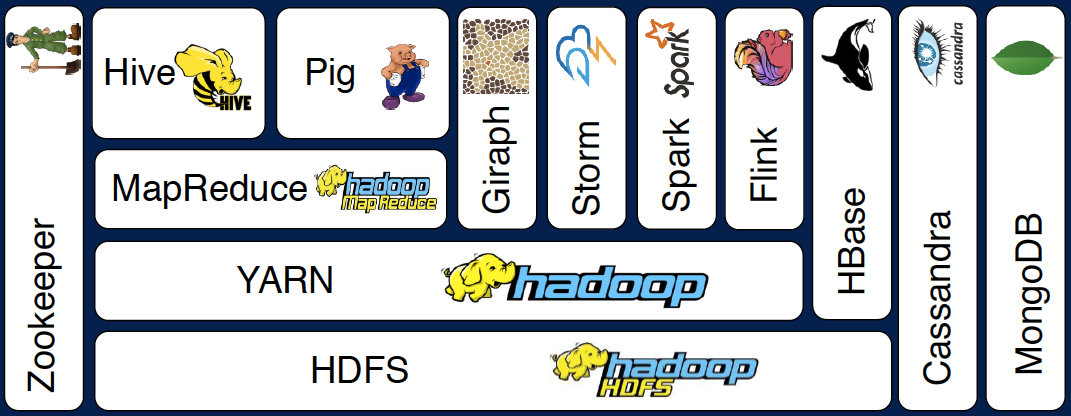 Figure 1: Spark vs Flink in the hadoop ecosystem (source)
Figure 1: Spark vs Flink in the hadoop ecosystem (source)
Now, let’s talk about Apache Flink and Apache Spark, the rockstars of the data processing world. Apache Spark sets the foundation of DataBricks, a startup that’s now worth a mind-blowing $43.01 billion as of September 2023. And guess what? It might just keep climbing, especially with the whole Generative AI craze.
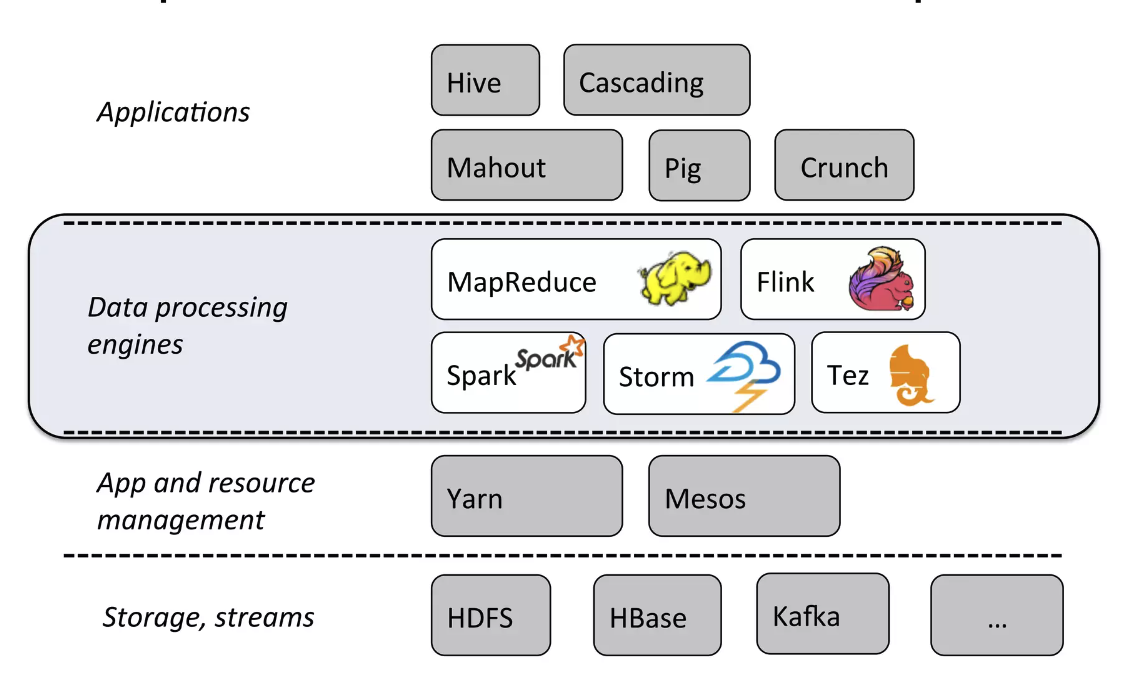 Figure 2: Spark vs Flink in the big data platform(source)
Figure 2: Spark vs Flink in the big data platform(source)
So, in this blog post, we’re gonna to compare these two platforms. We’ll break down the common design principles to build a big data processing platform, we will also highlight the different design choices of these two platforms. Stay tuned!
Apache Flink
Apache Flink provides high-throughput, low-latency streaming engineers as well as support for event-time processing and state management. In its core, apache flink implemented a distributed streaming data-flow engine written in Java and Scala.
Apache Flink introduced two fundamental data model: a DataStream API to describe streams of data, and a DataSet API for bounded data sets. Based on these two models, Apache Flink introduced the dataflow programming models. Engineers could apply transformations on these dataflows, these transformations could be arranged as a directed, acyclic dataflow graph, which branches and merged dataflows. In the very end, dataflows runs through sinks, which are the output of the application.
Apache Flink’s transformations could be stateful. Basically one execution node could gather and maintain state through the shared key-space, and through the configured time-window. State may be used to for something simple, such as counting events per minutes to display on a dashboard.
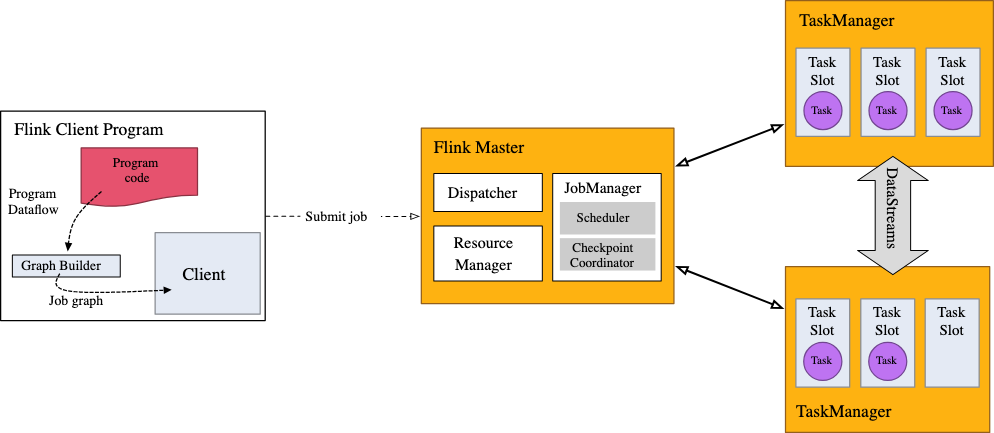 Figure 3: Apache Flink Architecture
Figure 3: Apache Flink Architecture
Apache Spark
Apache Spark got its fame because of its excellent performance compared with Hadoop. If using the in-memory RDD, Spark could be 100 times faster than hadoop. It specializes in batch processing, and introduces multiple new paradigm to improve the flexibility and efficiency of the computation.
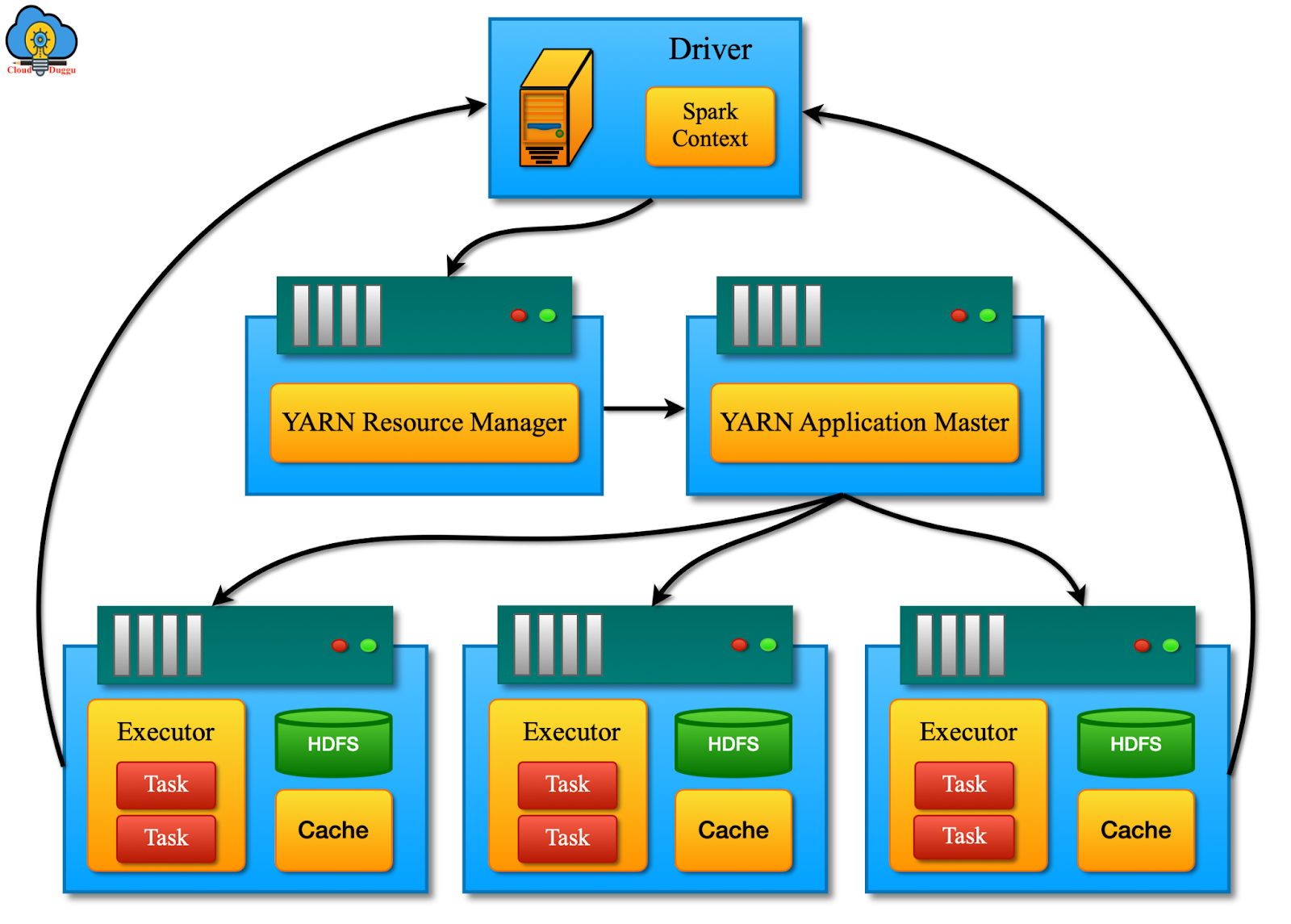 Figure 4: Apache Spark Architecture (YARN Mode) (source)
Figure 4: Apache Spark Architecture (YARN Mode) (source)
Spark introduced two main concepts: the resilient distributed dataset (RDD), and the directed acyclic graph (DAG).
RDD is read-only multiset of data items distributed over a fluster of machines and it is maintained in a fault-tolerant way. RDD was designed to address the limitation of the MapReduce, because MapReduce requires explicit Disk dump and load between each stage transitions.
On top of RDD, engineers could apply transformation to process data, each transformation will be stored for lazy execution, and apply the action function, which triggers computation. All these operations form a directed acyclic graph (DAG). In the graph, each node is a RDD, and the edge between two RDDs are transformations or actions.
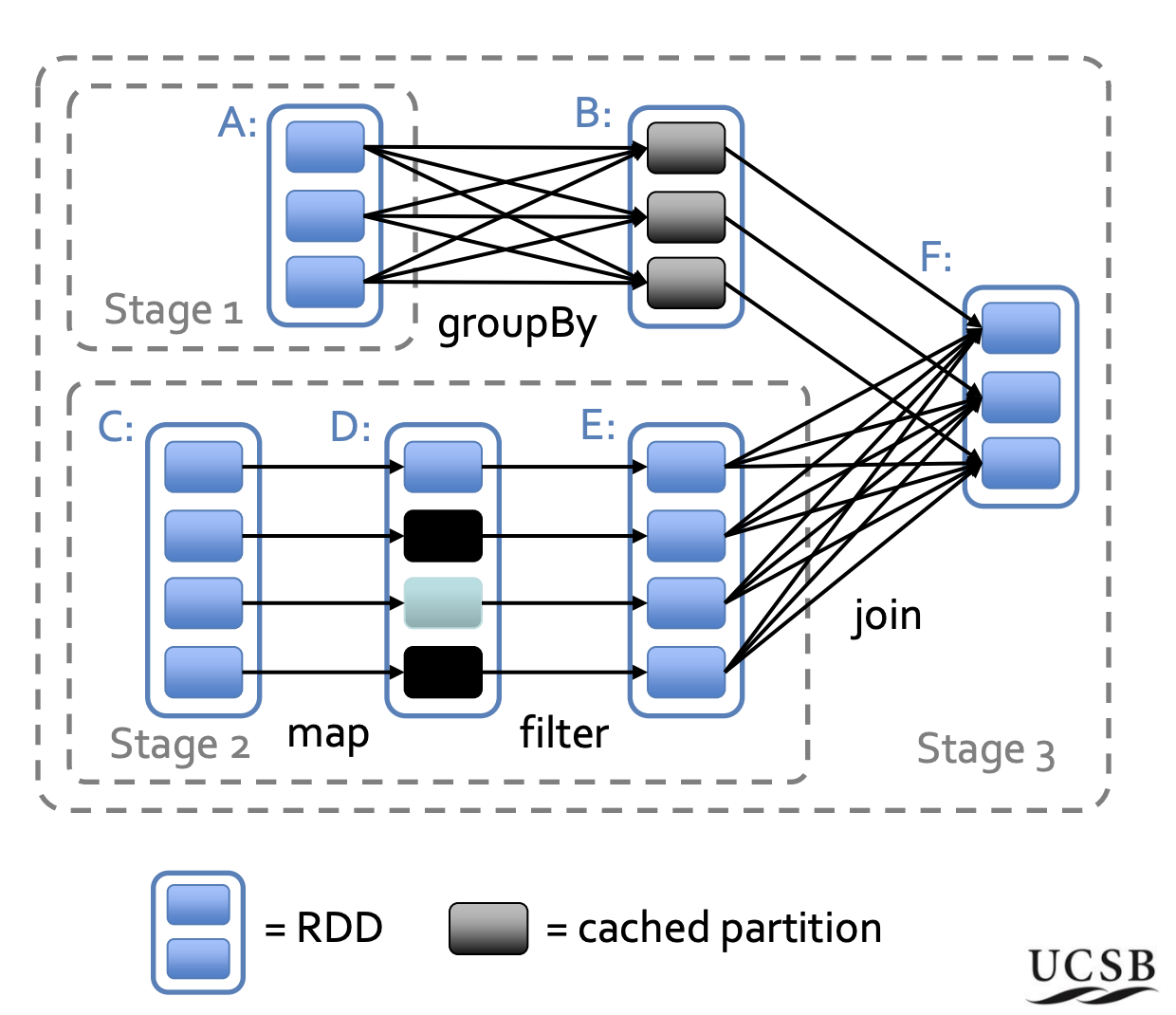 Figure 5: Spark RDD and DAG among stages(source)
Figure 5: Spark RDD and DAG among stages(source)
The RDD is designed to be fault tolerant. RDD data is always immutable, mutation (like transformation or action) generates new RDDs. One RDD could alway trace back to its parent and recompute. Once a RDD is computed, it could be kept in memory to be used for the next stage.
Apache Spark also supports real time analysis via streaming, but because of its core design of RDD, its streaming function is implemented via micro-batching, so it incurs a high latency because of the gating time of each micro-batch, in return, it is more efficient comparing with per-event based streaming solution, like Apache Flink.
Apache Spark supports multiple languages, including Java, Scala, Python, and R. Spark is implemented via Java/Scala, so support of these two languages is very straightforward. Python (PySpark) is implemented via the Py4j library. The support of python and R and also the RDD’s lazy computation and cache nature makes Spark very friendly for interactive exploration works that Data Scientists usually do in their jupyter notebook.
Common Design Principles of the Two Platforms
Apache Spark and Apache Flink share a list of high level design concepts, we could consider that as a common good practice of implementing a large scale data processing framework that could scale horizontally in data center clusters.
A Rich Client
If you consider Apache Flink or Apache Spark a super computer, you need a console to talk these super computer, this is where the client is used. Apache Spark’s client is also called the Driver program which owns the Spark Context of this application, it acts like a command center with the assistance of the cluster manager.
A List of Tasker Nodes
In Apache Flink, the tasker node is called Task Manager. In Apache Spark, these nodes are called worker nodes. Each worker node has its own cache and storage, and it could also run multiple tasks in parallel. The tasker nodes are the core worker horse that makes the platform horizontally scalable.
Write Once and Execute Everywhere
Both Apache Flink and Apache Spark allows the engineers to code the code in the client side, then it optimizes the execution plan based on the pipeline DAG and delivers the code to tasker node and executes there. The ability is generally referred to as write once and execute everywhere. It is the foundation for all the coordination and optimization of Flink and Spark.
For example, In a Spark REPL environent, spark compile the user code to class files and put on a file server, the executor implements a custom classloader which load the class from the file server on the driver side; the class is actually a function to run against a iterator of records, this is how the interaction mode delivers logic to worker nodes.
Support multiple layer’s programming interface
Most of the time, when we do business analytics, SQL is still our best friend, because everybody knows SQL, and SQL is very expressive. A big data analytical framework must support SQL. Both Apache Flink and Apache Spark support SQL based programming.
Apache Flink features two relational APIs - the Table API and SQL - for unified stream and batch processing. The Table API is a language-integrated query API for Java, Scala, and Python that allows the composition of queries from relational operators such as selection, filter, and join in a very intuitive way. Flink’s SQL support is based on Apache Calcite which implements the SQL standard. Queries specified in either interface have the same semantics and specify the same result regardless of whether the input is continuous (streaming) or bounded (batch).
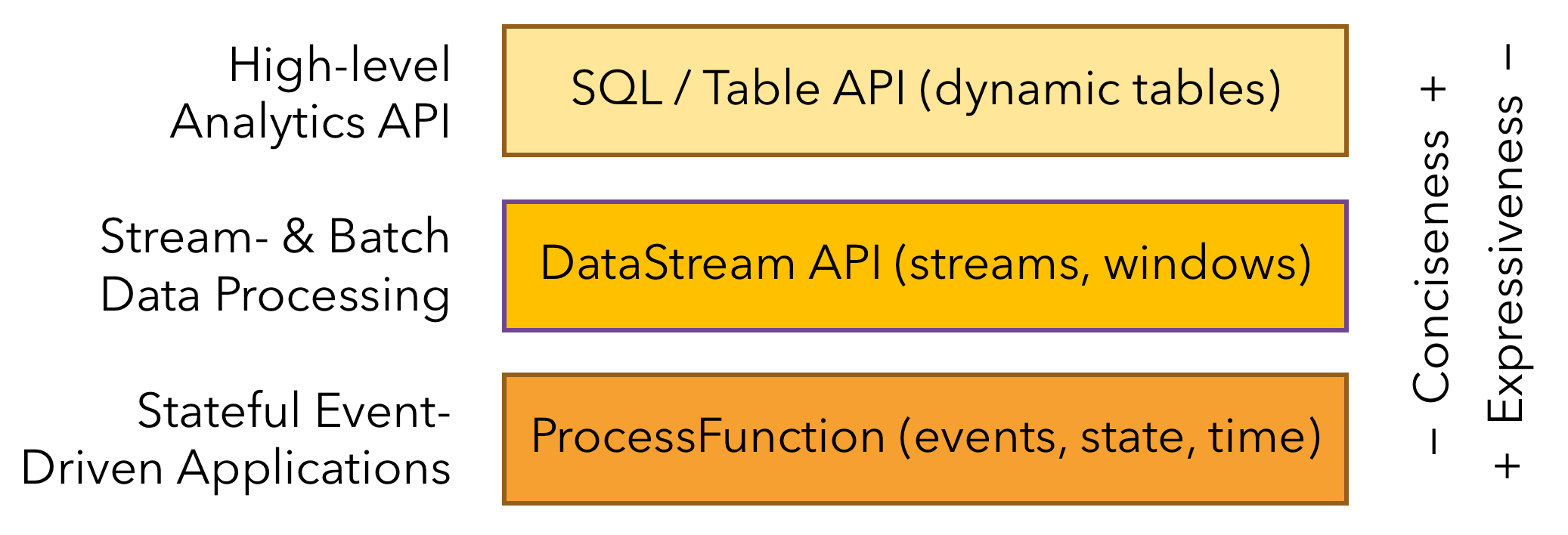 Figure 6:the layered APIs of Apache Flink
Figure 6:the layered APIs of Apache Flink
Apache Spark also implements SQL. Its SQL query operates directly on the RDD and external data sources like Hive Table.
Spark SQL is mainly used in the following scenarios:
- Import relational data from Parquet files and Hive tables
- Run SQL queries over imported data and existing RDDs
- Easily write RDDs out to Hive tables or Parquet files
Underneath the SQL, both Apache Flink and Apache Spark exposed their next layer of interface:
Apache Spark implemented Datasets, DataFrames. A Dataset is a distributed collection of data, it is a combination of the RDD functions and Spark SQL’s optimized execution engine. A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimization under the hood.
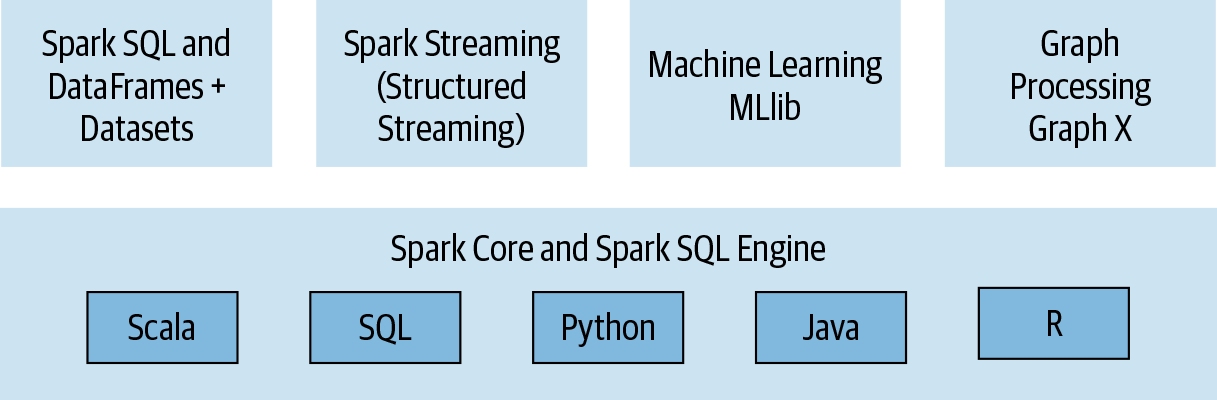 Figure 7:The API stack of Apache Spark
Figure 7:The API stack of Apache Spark
Hide Complexity from Engineers
Another common design principle of these two platforms is that lots of optimization and coordination are hidden away from the engineers. Engineers only need to define the input / output of the application, and define the hyper functions that transform the streams or the RDDs. These two platforms will take it from there, it will create the actual execution plan which is a DAG, run optimization and sharding of the DAG, then allocate task executors to execute plan and eventually export the result as configured. All the details of optimizing and executing such a complex task in a full distributed fashion is hidden away from the engineers, so engineers could focus on high level scoping.
Run Data Analysis with Apache Spark
Now, we are going to build an Apache Spark program to analyze web logs of a site that contains 1,000,000 visit records. The full notebook is at here.
First, we want to initialize the pyspark environment and load the log file as line based text, then parse the log line into structured row.
import pyspark
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import Row
appName = 'process-log-files'
path = "/kaggle/input/server-logs/logfiles.log"
spark = SparkSession \
.builder \
.appName(appName) \
.getOrCreate()
def parseLine(row):
line = row.value
tokens = line.split()
ip = tokens[0]
method = tokens[5][1:]
path = tokens[6]
status = tokens[8]
endPoint = f"{method} {path}"
return Row(ip=ip, method=method, path=path, status=status, endPoint=endPoint)
parsedRDD = spark.read.text(path) \
.rdd \
.map(parseLine)
Then we group all request logs by the request IPs, count the # of requests of each IP, then sort all records by visit count.
ipCountRddSorted = parsedRDD.groupBy(lambda r: r.ip)\
.map(lambda r: (r[0], len(list(r[1])))) \
.sortBy(lambda r: r[1], ascending=False)
ipCountRddSorted.take(5)
The top 5 IP with the most requests are
[
('46.239.178.40', 2),
('110.109.131.215', 2),
('75.34.183.185', 2),
('44.100.225.119', 2),
('31.58.205.61', 2)
]
As the result shows, each IP sends out at most 2 requests, we do not have a lot of requests from certain IPs.
Now let’s find the most popular endpoints, and their traffic
endpointCountRddSorted = parsedRDD.groupBy(lambda r: r.endPoint)\
.map(lambda r: (r[0], len(list(r[1])))) \
.sortBy(lambda r: r[1], ascending=False)
endpointCountRddSorted.take(5)
The top 5 most visited endpoints are
[
('PUT /usr/register', 50515),
('GET /usr/login', 50480),
('PUT /usr/admin/developer', 50179),
('GET /usr', 50158),
('DELETE /usr', 50138)
]
As this sample application shows, with Apache Spark, we could quick write analysis code with a few lines of code. These code will be submitted to a task manager to execute via a big apache spark cluster, with this, we could write a few line’s code to analyze the web scale data, and we do not need to worry about all the messy details of build distributed systems.